
Last Updated: 2023-03-06
Kubernetes
Kubernetes is an open source project (available on kubernetes.io) which can run on many different environments, from laptops to high-availability multi-node clusters, from public clouds to on-premise deployments, from virtual machines to bare metal.
For the purpose of this codelab, using an environment set up by Kops will allow you to focus more on experiencing Kubernetes rather than setting up the underlying infrastructure but you can choose any other managed solution or environment (i.e. EKS) instead.
What you'll build
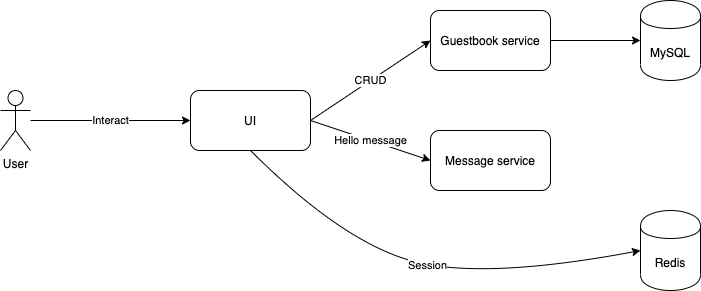
In this codelab, you're going to deploy a guestbook microservice app using Kubernetes. Your app will:
- Consist of 3 services
- Use Redis to cache sessions.
- Use MySQL for persistence.
What you'll need
- A recent version of your favorite Web Browser
- Basics of BASH
- EC2 instance with
kops-instancerole in our AWS Account
Before you can use Kubernetes to deploy your application, you need a cluster of machines to deploy them to. The cluster abstracts the details of the underlying machines you deploy to the cluster.
Machines can later be added, removed, or rebooted and containers are automatically distributed or re-distributed across whatever machines are available in the cluster. Machines within a cluster can be set to autoscale up or down to meet demand. Machines can be located in different zones for high availability.
Open Cloud Shell
You will do some of the work from the Amazon Cloud Shell, a command line environment running in the Cloud. This virtual machine is loaded with all the development tools you'll need (aws cli, python) and offers a persistent 1GB home directory and runs in AWS, greatly enhancing network performance and authentication. Open the Amazon Cloud Shell by clicking on the icon on the top right of the screen:

You should see the shell prompt open in the new tab:
Initial setup
Before creating a cluster, you must install and configure the following tools:
kubectl– A command line tool for working with Kubernetes clusters.kops– A command line tool for Kubernetes clusters in the AWS Cloud.
To install kops, run the following:
$ curl -Lo kops https://github.com/kubernetes/kops/releases/download/$(curl -s https://api.github.com/repos/kubernetes/kops/releases/latest | grep tag_name | cut -d '"' -f 4)/kops-linux-amd64
$ chmod +x ./kops
$ sudo mv ./kops /usr/local/bin/Confirm the kops command works:
$ kops versionTo install kubectl, run the following:
$ curl -Lo kubectl https://storage.googleapis.com/kubernetes-release/release/$(curl -s https://storage.googleapis.com/kubernetes-release/release/stable.txt)/bin/linux/amd64/kubectl
$ chmod +x ./kubectl
$ sudo mv ./kubectl /usr/local/bin/kubectlkops needs a state store to hold the configuration for your clusters. The simplest configuration for AWS is to store it in a S3 bucket in the same account, so that's how we'll start.
Create an empty bucket, replacing YOUR_NAME with your name 😁:
$ export REGION=us-east-1
$ export STATE_BUCKET=YOUR_NAME-state-store
# Create the bucket using awscli
$ aws s3api create-bucket \
--bucket ${STATE_BUCKET} \
--region ${REGION}If the name is taken and you receive an error - change the name and try again.
Next, rather than typing the different command argument every time, it's much easier to export the KOPS_STATE_STORE and NAME variables to previously setup bucket name and a cluster name that ends with .k8s.local, for example:
$ export NAME="mycoolcluster.k8s.local" #SHOULD END WITH .k8s.local
$ export KOPS_STATE_STORE="s3://${STATE_BUCKET}"After that - generate a dummy SSH key for kops to use:
$ ssh-keygen -b 2048 -t rsa -f ${HOME}/.ssh/id_rsa -q -N ""Create Cluster
Now you are ready to create the cluster. We're going to create a production ready high availability cluster with 3 masters and 4 nodes:
$ kops create cluster \
--name ${NAME} \
--state ${KOPS_STATE_STORE} \
--node-count 4 \
--master-count=3 \
--zones us-east-1a \
--master-zones us-east-1a,us-east-1b,us-east-1c \
--node-size t2.medium \
--master-size t2.medium \
--master-volume-size=20 \
--node-volume-size=20 \
--networking flannel \
--cloud-labels "ita_group=devops"When cluster configuration is ready, edit it:
$ kops edit cluster ${NAME}In the editor - find the start of spec that looks like this:
...
spec:
api:
loadBalancer:
class: Classic
type: Public
...Edit it so it looks like the next snippet:
...
spec:
certManager:
enabled: true
metricsServer:
enabled: true
insecure: false
api:
loadBalancer:
class: Classic
type: Public
...Next, find the iam section at the end of the spec that looks like this:
...
spec:
...
iam:
allowContainerRegistry: true
legacy: false
...Edit it so it looks like the next snippet:
...
spec:
...
iam:
allowContainerRegistry: true
legacy: false
permissionsBoundary: arn:aws:iam::ACCOUNT_ID_HERE:policy/CustomPowerUserBound
...After saving the document, run the following set of commands:
$ kops update cluster ${NAME} --yes --adminWait 5-10 minutes till the cluster is ready. You can check its state by periodically running validate:
$ kops validate cluster --wait 10m
....
Your cluster mycoolcluster.k8s.local is readyInitial setup
In the real world you may, for example, want to deploy your application with 1 replica in the Dev environment, 2 replicas in staging, and 10 replicas in Production. Rather than setting those as variables and using a homegrown templating engine, you can use Kustomize to edit these attributes. Kustomize allows you to quickly re-use and edit existing Kubernetes manifests for different target environments.
$ curl -s "https://raw.githubusercontent.com/\
kubernetes-sigs/kustomize/master/hack/install_kustomize.sh" | bash
$ sudo mv kustomize /usr/local/bin/kustomizeGet the application sources
Start by cloning the repository for our Guestbook application.
$ cd ~/
$ git clone https://gitlab.com/DmyMi/aws-k8s-labSetup Amazon ECR
Amazon EC2 Container Registry (ECR) is a fully-managed Docker container registry that makes it easy for developers to store, manage, and deploy Docker container images. Amazon ECR eliminates the need to operate your own container repositories or worry about scaling the underlying infrastructure. Amazon ECR hosts your images in a highly available and scalable architecture, allowing you to reliably deploy containers for your applications. Integration with AWS Identity and Access Management (IAM) provides resource-level control of each repository. With Amazon ECR, there are no upfront fees or commitments. You pay only for the amount of data you store in your repositories and data transferred to the Internet.
Export the required variables.:
$ export ACCOUNT_ID=`aws sts get-caller-identity --query "Account" --output text`
$ export REGION="us-east-1"
$ export REPO_PREFIX="your-name"After that you can run the following command to create 3 repositories for the demo project. You can copy & paste it in the console.
for name in "ui" "message" "guestbook" "kpack"
do
/usr/local/bin/aws ecr create-repository \
--repository-name "${REPO_PREFIX}"-"${name}" \
--image-scanning-configuration scanOnPush=true \
--region "${REGION}"
doneGet ECR Token
To be able to build images inside the cluster and push to ECR we need to have an ECR access token.
Use AWS CLI to get the access token for AWS ECR in the us-east-1 region.
$ TOKEN=`aws ecr get-login-password --region ${REGION} | cut -d' ' -f6`With the token available, we need to save it in the cluster for later access by our helper pods. As this token is used to access a Docker registry, we can use a special Kubernetes Secret type kubernetes.io/dockerconfigjson that allows us to store Docker credentials in standard manner.
$ kubectl create secret docker-registry ecr-secret \
--docker-server=https://${ACCOUNT_ID}.dkr.ecr.${REGION}.amazonaws.com \
--docker-username=AWS \
--docker-password="${TOKEN}"Install kpack
As Cloud Shell doesn't have enough compute power and functionality to build Docker images we will use our cluster to do it. We will utilize kpack, which extends Kubernetes and utilizes unprivileged kubernetes primitives to provide builds of OCI images as a platform implementation of Cloud Native Buildpacks.
kpack provides a declarative builder resource that configures a Cloud Native Buildpacks build configuration with the desired buildpack order and operating system stack.
kpack provides a declarative image resource that builds an OCI image and schedules rebuilds on source changes and from builder buildpack and builder stack updates.
To install kpack run the following command:
$ kubectl apply -f https://github.com/pivotal/kpack/releases/download/v0.10.1/release-0.10.1.yamlTo be able to deeper inspect several kpack primitives we can use kpack-cli.
$ KP_VERSION=$(curl -s https://api.github.com/repos/vmware-tanzu/kpack-cli/releases/latest | grep tag_name | cut -d '"' -f 4)
$ curl -Lo kp https://github.com/vmware-tanzu/kpack-cli/releases/download/${KP_VERSION}/kp-linux-amd64-${KP_VERSION:1}
$ chmod +x ./kp
$ sudo mv ./kp /usr/local/bin/Setup kpack
To be able to use kpack we need several Kubernetes resources (both basic and custom):
- Service account that references the registry secret.
- Cluster store configuration. A store resource is a repository of buildpacks packaged in buildpackages that can be used by
kpackto build OCI images. - Cluster stack configuration. A stack resource is the specification for a cloud native buildpacks stack used during build and in the resulting application image.
- Builder configuration. A Builder is the
kpackconfiguration for a builder image that includes the stack and buildpacks needed to build an OCI image from your application source code. The Builder configuration will write to the registry using the credentials from the secret we've created and will reference the stack and store. The builder order will determine the order in which buildpacks are used in the builder.
Use the following command to create these resources:
$ cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: ServiceAccount
metadata:
name: kp-sa
secrets:
- name: ecr-secret
imagePullSecrets:
- name: ecr-secret
---
apiVersion: kpack.io/v1alpha2
kind: ClusterStore
metadata:
name: default
spec:
sources:
- image: gcr.io/paketo-buildpacks/java
---
apiVersion: kpack.io/v1alpha2
kind: ClusterStack
metadata:
name: base
spec:
id: "io.buildpacks.stacks.bionic"
buildImage:
image: "paketobuildpacks/build:base-cnb"
runImage:
image: "paketobuildpacks/run:base-cnb"
---
apiVersion: kpack.io/v1alpha2
kind: Builder
metadata:
name: builder
spec:
serviceAccountName: kp-sa
tag: ${ACCOUNT_ID}.dkr.ecr.${REGION}.amazonaws.com/${REPO_PREFIX}-kpack:builder
stack:
name: base
kind: ClusterStack
store:
name: default
kind: ClusterStore
order:
- group:
- id: paketo-buildpacks/java
EOFBuild images and push to ECR
Create Image resources to build our images. An image resource is the specification for an OCI image that kpack should build and manage. We will have separate image resources for all our applications.
$ cat <<EOF | kubectl apply -f -
apiVersion: kpack.io/v1alpha2
kind: Image
metadata:
name: ui-image
spec:
tag: ${ACCOUNT_ID}.dkr.ecr.${REGION}.amazonaws.com/${REPO_PREFIX}-ui:v1
serviceAccountName: kp-sa
builder:
name: builder
kind: Builder
source:
git:
url: https://gitlab.com/DmyMi/aws-k8s-lab.git
revision: master
build:
env:
- name: "BP_GRADLE_BUILT_MODULE"
value: "ui"
---
apiVersion: kpack.io/v1alpha2
kind: Image
metadata:
name: message-image
spec:
tag: ${ACCOUNT_ID}.dkr.ecr.${REGION}.amazonaws.com/${REPO_PREFIX}-message:v1
serviceAccountName: kp-sa
builder:
name: builder
kind: Builder
source:
git:
url: https://gitlab.com/DmyMi/aws-k8s-lab.git
revision: master
build:
env:
- name: "BP_GRADLE_BUILT_MODULE"
value: "message"
---
apiVersion: kpack.io/v1alpha2
kind: Image
metadata:
name: guestbook-image
spec:
tag: ${ACCOUNT_ID}.dkr.ecr.${REGION}.amazonaws.com/${REPO_PREFIX}-guestbook:v1
serviceAccountName: kp-sa
builder:
name: builder
kind: Builder
source:
git:
url: https://gitlab.com/DmyMi/aws-k8s-lab.git
revision: master
build:
env:
- name: "BP_GRADLE_BUILT_MODULE"
value: "guestbook"
EOFYou can check if images are built by running the following command:
$ kubectl get imagesYou can watch the build logs by using kp build logs IMAGE_NAME, e.g.:
$ kp build logs ui-imageIf everything went fine - you will see a list of images with URLs and READY=True
Example directory
Move into the Kubernetes examples directory.
$ cd ~/aws-k8s-lab/kubernetes/You will be using the yaml files in this directory. Every file describes a resource that needs to be deployed into Kubernetes.
To edit the repository names - execute the following script:
for name in "guestbook-deployment" "message-deployment" "ui-deployment"
do
/usr/bin/sed "s/AWS_ACCOUNT_ID/${ACCOUNT_ID}/g" "${name}".yaml.tpl | \
/usr/bin/sed "s/AWS_REPO_PREFIX/${REPO_PREFIX}/g" > "${name}".yaml
done
Redis deployment
A Kubernetes pod is a group of containers, tied together for the purposes of administration and networking. It can contain one or more containers. All containers within a single pod will share the same networking interface, IP address, volumes, etc. All containers within the same pod instance will live and die together. It's especially useful when you have, for example, a container that runs the application, and another container that periodically polls logs/metrics from the application container.
You can start a single Pod in Kubernetes by creating a Pod resource. However, a Pod created this way would be known as a Naked Pod. If a Naked Pod dies/exits, it will not be restarted by Kubernetes. A better way to start a pod is by using a higher-level construct such as a Deployment.
Deployment provides declarative updates for Pods and Replica Sets. You only need to describe the desired state in a Deployment object, and the Deployment controller will change the actual state to the desired state at a controlled rate for you. It does this using an object called a ReplicaSet under the covers. You can use deployments to easily:
- Create a Deployment to bring up a ReplicaSet and Pods.
- Check the status of a Deployment to see if it succeeds or not.
- Later, update that Deployment to recreate the Pods (for example, to use a new image, or configuration).
- Rollback to an earlier Deployment revision if the current Deployment isn't stable.
- Pause and resume a Deployment.
Open the redis-deployment.yaml to examine the deployment descriptor. You can use your favorite editor such as Cloud Shell Editor, vi, emacs, or nano.
First create a Pod using kubectl, the Kubernetes CLI tool:
$ kubectl apply -f redis-deployment.yamlYou should see a Redis instance running
$ kubectl get podsNote down the Pod name, you can kill this Redis instance
$ export REDIS_POD=$(kubectl get pods -l app=redis -o jsonpath='{.items[0].metadata.name}')
$ kubectl delete pod $REDIS_PODKubernetes will automatically restart this pod for you (lets see some additional info):
$ kubectl get pods -owideYou can also launch a command or start a shell directly within the container using kubectl exec command. Let's get the new pod name and open a shell inside of the Redis container:
$ export REDIS_POD=$(kubectl get pods -l app=redis -o jsonpath='{.items[0].metadata.name}')
$ kubectl exec -ti $REDIS_POD -- /bin/bash
root@redis...:/data# ls /
bin boot data dev etc home ...The Pod name is automatically assigned as the hostname of the container. Each Pod is also automatically assigned an ephemeral internal IP address:
root@redis...:/data# hostname
redis-....
root@redis...:/data# hostname -i
100.x.x.x
root@redis...:/data# exitLastly, any of the container output to STDOUT and STDERR will be accessible as Kubernetes logs:
$ kubectl logs $REDIS_PODYou can also see the logs in realtime:
$ kubectl logs --follow $REDIS_PODPress Ctrl + C to exit.
Redis Service
Each Pod has a unique IP address - but the address is ephemeral. The Pod IP addresses are not stable and it can change when Pods start and/or restart. A service provides a single access point to a set of pods matching some constraints. A Service IP address is stable.
Open the redis-service.yaml to examine the service descriptor. The important part about this file is the selector section. This is how a service knows which pod to route the traffic to, by matching the selector labels with the labels of the pods:
kind: Service
apiVersion: v1
metadata:
name: redis
labels:
app: redis
spec:
ports:
- port: 6379
targetPort: 6379
protocol: TCP
selector:
app: redisCreate the Redis service:
$ kubectl apply -f redis-service.yamlAnd check it:
$ kubectl get svc
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes 10.x.x.x <none> 443/TCP 10m
redis 10.x.x.x <none> 6379/TCP 30sMySQL StatefulSet and Service
MySQL uses persistent storage. Rather than writing the data directly into the container image itself, our example stores the MySQL in a Persistent Disk volume.
Also, our database instance is stateful (i.e., stores instance-specific data), we'll run into issues quickly if we use a normal Kubernetes Deployment, because each of the replicas will be pointing to exactly the same persistent volume for storage - and it may not work.
Not only that, but if we set up replication then each Pod will have an ephemeral Pod name, making it impossible to tell which Pod is the primary/master/first.
With StatefulSet, each Pod can have its own persistent volumes - and the names become stable, i.e., the first instance of the StatefulSet will have the ID of 0, and the second instance will have ID of 1.
We can deploy MySQL as a StatefulSet:
$ kubectl apply -f mysql-stateful.yamlIn this YAML file, notice of a couple of important details:
- The kind is a StatefulSet rather than a Deployment or ReplicaSet
- If you increase replica count - you can depend on
mysql-0being provisioned beforemysql-1. Provision of the instances is sequential, from the first instance to the number of replicas you need. volumeClaimTemplatesis used to automatically generate a new Persistent Volume Claim, and subsequently, this will automatically provision a disk in GCP with the specified capacity. We don't need to create a Persistent Disk manually.
Open the mysql-stateful.yaml to examine the service descriptor. The important part about this file is the volumeClaimTemplates and volumeMounts section. This section describes that the Pod needs to use a Persistent Disk volume that will be created automatically, and also mounting that disk into a path specific to the MySQL container.
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: mysql
labels:
app: mysql
spec:
serviceName: "mysql"
replicas: 1
selector:
matchLabels:
app: mysql
template:
metadata:
labels:
app: mysql
spec:
containers:
- name: mysql
...
volumeMounts:
# name must match the volume name below
- name: mysql-persistent-storage
# mount path within the container
mountPath: /var/lib/mysql
volumeClaimTemplates:
- metadata:
name: mysql-persistent-storage
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "default"
resources:
requests:
storage: 5GiNow you can deploy the Service:
$ kubectl apply -f mysql-service.yamlLastly, you can see the Pods and service status via the command line. Recall the command you can use to see the status (hint: kubectl get ...). Make sure the status is Running before continuing.
We have two separate services to deploy:
- the Guestbook service (that writes to the MySQL database)
- a Message service
Both services are containers whose images contain compiled Java class files. The source is available in the respective directories if you are interested in seeing it.
When deploying these microservices instances, we want to make sure that:
- We can scale the number of instances once deployed.
- If any of the instances becomes unhealthy and/or fails, we want to make sure they are restarted automatically.
- If any of the machines that run the service is down (scheduled or unscheduled), we need to reschedule the microservice instances to another machine.
Create a new base directory for our kustomizations and move files there:
$ mkdir -p ~/aws-k8s-lab/kubernetes/base
$ cd ~/aws-k8s-lab/kubernetes/
$ cp {guestbook-deployment.yaml,guestbook-service.yaml,message-deployment.yaml,message-service.yaml,ui-deployment.yaml,ui-service.yaml} ./baseCreate a kustomization.yaml:
$ cd ~/aws-k8s-lab/kubernetes/base
$ kustomize create
$ kustomize edit add resource {guestbook-deployment.yaml,guestbook-service.yaml,message-deployment.yaml,message-service.yaml}This will create a kustomization.yaml with the 4 YAMLs as the base manifests. Verify that resources are added:
$ cat kustomization.yaml
apiVersion: kustomize.config.k8s.io/v1beta1
kind: Kustomization
resources:
- guestbook-deployment.yaml
- guestbook-service.yaml
- message-deployment.yaml
- message-service.yamlUse Kustomize to combine the 4 manifests into a single deployable manifest.
$ kustomize buildYou can also apply it directly to Kubernetes:
$ kustomize build | kubectl apply -f -Once created, you can see the replicas with:
$ kubectl get deployment
NAME READY UP-TO-DATE AVAILABLE AGE
guestbook-service 2/2 2 2 33s
message-service 2/2 2 2 33s
redis 1/1 1 1 19mThe Deployment, behind the scenes, creates a Replica Set. A Replica Set ensures the number of replicas (instances) you need to run at any given time. You can also see the Replica Set:
$ kubectl get rsNotice that because we also used Deployment to deploy Redis - each of those deployments created its own Replica Set as well. Our descriptor file specified 2 replicas. So, if you delete one of the pods (and now you only have 1 replica rather than 2), the Replica Set will notice that and start another pod for you to meet the configured 2 replicas specification.
But the MySQL is not there, you can see it has its own controller by using:
$ kubectl get statefulsetSince we are running two instances of the Message Service (one instance in one pod), and that the IP addresses are not only unique, but also ephemeral - how will a client reach our services? We need a way to discover the service.
In Kubernetes, Service Discovery is a first class citizen. We created a Service that will:
- act as a load balancer to load balance the requests to the pods, and
- provide a stable IP address, allow discovery from the API, and also create a DNS name!
If you login into a container (use Redis container for it), you can access the message-service via the DNS name:
$ export REDIS_POD=$(kubectl get pods -l app=redis -o jsonpath='{.items[0].metadata.name}')
$ kubectl exec -ti $REDIS_POD -- /bin/bash
root@redis:/# wget -qO- http://message-service:80/hello/Test
{"greeting":"Hello Test from message-service-... with 1.0","hostname":"message-service-...","version":"1.0"}
root@redis:/# exitYou know the drill by now.
$ cd ~/aws-k8s-lab/kubernetes/base
$ kustomize edit add resource {ui-deployment.yaml,ui-service.yaml}Update the application stack deployment by running the following to launch our UI Service.
$ kustomize build | kubectl apply -f -But how are our users going to access the application? We need to expose it to the external world. We can use a LoadBalancer service, but if we have multiple applications - we will have to pay for extra Amazon LoadBalancers. So we will use an Ingress.
Ingress exposes HTTP and HTTPS routes from outside the cluster to services within the cluster. Traffic routing is controlled by rules defined on the Ingress resource.
An Ingress may be configured to give Services externally-reachable URLs, load balance traffic, terminate SSL / TLS, and offer name based virtual hosting. An Ingress controller is responsible for fulfilling the Ingress, usually with a load balancer, though it may also configure your edge router or additional front ends to help handle the traffic.
An Ingress does not expose arbitrary ports or protocols. Exposing services other than HTTP and HTTPS to the internet typically uses a service of type Service.Type=NodePort or Service.Type=LoadBalancer.
First, let's create an ingress controller that is going to do all the hard work. Run the script that will install a Kubernetes supported NGINX Controller that can work with Amazon LoadBalancers.
$ kubectl apply -f https://raw.githubusercontent.com/kubernetes/ingress-nginx/controller-v1.7.0/deploy/static/provider/aws/deploy.yamlWait for 2-5 minutes and find the LoadBalancer address in the "External IP" section of the output that we will use later to access the application:
$ export INGRESS_URL=`kubectl get svc ingress-nginx-controller -n ingress-nginx -o=jsonpath={.status.loadBalancer.ingress[0].hostname}`
$ echo http://${INGRESS_URL}Now that we have a controller we can set up our rules to actually route traffic to our application. Let's check out the ingress descriptor in ui-ingress.yaml. It tells the controller where to redirect requests depending on http paths.
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ui-ingress
annotations:
kubernetes.io/ingress.class: nginx
nginx.ingress.kubernetes.io/rewrite-target: /
spec:
rules:
- http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: ui
port:
number: 80Deploy the ingress:
$ cd ~/aws-k8s-lab/kubernetes
$ kubectl apply -f ui-ingress.yamlFinally, checkout the application using the ingress LoadBalancer address you got earlier in a new browser tab.
Scaling the number of replicas of any of our services is as simple as running:
$ kubectl scale --replicas=4 deployment/message-serviceYou can very quickly see that the deployment has been updated:
$ kubectl get deployment
$ kubectl get podsLet's scale out even more!
$ kubectl scale --replicas=60 deployment/message-serviceLet's take a look at the status of the Pods:
$ kubectl get podsOh no! Some of the Pods are in the Pending state! That is because we only have 3-5 physical nodes, and the underlying infrastructure has run out of capacity to run the containers with the requested resources.
Pick a Pod name that is associated with the Pending state to confirm the lack of resources in the detailed status:
$ kubectl describe pod message-service...The good news is that we can easily spin up more EC2 instances to append to the cluster. You can edit the nodes instance group with kops and add more nodes and see that pods are scheduled. This is left for you to exercise. Check this documentation :)
Once you're done - reduce the number of replicas back to 2 so that we can free up resources for the later parts of the lab:
$ kubectl scale --replicas=2 deployment/message-serviceIt's easy to update & rollback.
Rolling Update
In this lab, we made a minor change to the index.html (changed the background color).
Build and push a new version to ECR using a modified revision in image config.
$ cat <<EOF | kubectl apply -f -
apiVersion: kpack.io/v1alpha2
kind: Image
metadata:
name: ui-image-v2
spec:
tag: ${ACCOUNT_ID}.dkr.ecr.${REGION}.amazonaws.com/${REPO_PREFIX}-ui:v2
serviceAccountName: kp-sa
builder:
name: builder
kind: Builder
source:
git:
url: https://gitlab.com/DmyMi/aws-k8s-lab.git
revision: v2
build:
env:
- name: "BP_GRADLE_BUILT_MODULE"
value: "ui"
EOFWait for 2-5 minutes before continuing. You can check progress by running:
$ kp build logs ui-image-v2Because we are managing our Pods with Deployment, it simplifies re-deployment with a new image and configuration.
Edit kustomization.yaml and add the new image tag.
$ cd ~/aws-k8s-lab/kubernetes/base
$ kustomize edit set image ${ACCOUNT_ID}.dkr.ecr.us-east-1.amazonaws.com/${REPO_PREFIX}-ui=${ACCOUNT_ID}.dkr.ecr.us-east-1.amazonaws.com/${REPO_PREFIX}-ui:v2Apply the file:
$ kustomize build | kubectl apply -f -That's it! Kubernetes will then perform a rolling update to update all the versions from 1.0 to 2.0. Wait 1-2 minutes and check the ui again or run watch kubectl get pod to see the progress of update.
Rollback a Deployment
You can see your deployment history:
$ kubectl rollout history deployment uiYou can rollback a Deployment to a previous revision:
$ kubectl rollout undo deployment ui
deployment "ui" rolled backA single cluster can be split into multiple namespaces. Resource names (like Deployment, Service, etc) need to be unique within a namespace, but can be reused in different namespaces. i.e., you can create a namespace staging and a namespace qa. You can deploy exactly the same application into both namespaces. Each namespace can also have its own resource constraint. i.e., qa namespace can be assigned a 10 CPU cores limit while staging namespace can have more.
Create a new namespace:
$ kubectl create ns stagingSee what's deployed there:
$ kubectl --namespace=staging get pods
No resources found.Let's deploy something!
$ cd ~/aws-k8s-lab/kubernetes/
$ kubectl --namespace=staging apply \
-f mysql-stateful.yaml \
-f mysql-service.yaml \
-f redis-deployment.yaml \
-f redis-service.yamlIt's hard to remember every manifest you need. Kustomize to the rescue!
Let's create an overlay to our base configuration to easily change namespaces during deployment:
$ mkdir -p ~/aws-k8s-lab/kubernetes/staging
$ cd ~/aws-k8s-lab/kubernetes/staging
$ kustomize create --resources ../base --namespace stagingThe entire application is now deployed into staging namespace:
$ cd ~/aws-k8s-lab/kubernetes/
$ kustomize build staging | kubectl apply -f -See what's deployed with:
$ kubectl --namespace=staging get podsIf you ever need to remove an entire environment under a namespace, simply delete the namespace:
$ kubectl delete namespace staging
namespace "staging" deletedThis will propagate and delete every resource under this namespace, including automatically provisioned external load balancers, and volumes. The operations are asynchronous. Even though the command line says the namespace was deleted - the resources are still being deleted asynchronously.
You can specify the resource needs for each of the containers within the Deployment descriptor file. By default, each container is given 10% of a CPU and no memory use restrictions. You can see the current resource by describing a Pod instance, look for the Requests/Limits lines.
$ kubectl get pods
$ kubectl describe pod message-service...In Kubernetes, you can reserve capacity by setting the Resource Requests to reserve more CPU and memory.
apiVersion: apps/v1
kind: Deployment
metadata:
...
spec:
...
template:
...
spec:
containers:
- name: message-service
image: img-name:v2
resources:
requests:
cpu: 200m
memory: 256Mi
...If the application needs to consume more CPU - that's OK as well, the applications are allowed to burst. You can also set an upper limit to how much the application burst by setting the Resource Limit:
apiVersion: apps/v1
kind: Deployment
metadata:
...
spec:
...
template:
...
spec:
containers:
- name: message-service
image: img-name:v2
resources:
requests:
...
limits:
cpu: 500m
memory: 512Mi
...Create a file message-patch.yaml.
$ vi ~/aws-k8s-lab/kubernetes/base/message-patch.yamlwith the following content:
apiVersion: apps/v1
kind: Deployment
metadata:
name: message-service
spec:
template:
spec:
containers:
- name: message-service
env:
- name: JAVA_TOOL_OPTIONS
value: "-XX:ReservedCodeCacheSize=128M"
resources:
requests:
cpu: 200m
memory: 256Mi
limits:
cpu: 500m
memory: 512MiNext, use Kustomize to add this patch to our Message Service manifest:
$ cd ~/aws-k8s-lab/kubernetes/base/
$ kustomize edit add patch --path message-patch.yamlThis will allow us to dynamically modify the deployment without altering the original file.
Redeploy the application to apply the new configuration:
$ cd ~/aws-k8s-lab/kubernetes/
$ kustomize build base | kubectl apply -f -During rolling update, a pod is removed as soon as a newer version of pod is up and ready to serve. By default, without health checks, Kubernetes will route traffic to the new pod as soon as the pods starts. But, it's most likely that your application will take some time to start, and if you route traffic to the application that isn't ready to serve, your users (and/or consuming services) will see errors. To avoid this, Kubernetes comes with two types of checks: Liveness Probe, and Readiness Probe.
After a container starts, it is not marked as Healthy until the Liveness Probe succeeds. However, if the number of Liveness Probe failures exceeds a configurable failure threshold, Kubernetes will mark the pod unhealthy and attempt to restart the pod.
When a pod is Healthy doesn't mean it's ready to serve. You may want to warm up requests/cache, and/or transfer state from other instances. You can further mark when the pod is Ready to serve by using a Readiness Probe.
For example, the Liveness/Readiness probes can look like this:
apiVersion: apps/v1
kind: Deployment
metadata:
...
spec:
...
template:
...
spec:
containers:
- name: ...
...
readinessProbe:
httpGet:
path: /
port: 8080
livenessProbe:
initialDelaySeconds: 60
httpGet:
port: 8080
path: /
...Create a file ui-patch.yaml
$ vi ~/aws-k8s-lab/kubernetes/base/ui-patch.yamlwith the Liveness Probe/Readiness probes for our UI Service:
apiVersion: apps/v1
kind: Deployment
metadata:
name: ui
spec:
template:
spec:
containers:
- name: ui
readinessProbe:
initialDelaySeconds: 40
httpGet:
path: /actuator/health
port: 9000
livenessProbe:
initialDelaySeconds: 60
httpGet:
port: 9000
path: /actuator/healthNext, use Kustomize to add this patch to our UI manifest:
$ cd ~/aws-k8s-lab/kubernetes/base/
$ kustomize edit add patch --path ui-patch.yamlRedeploy the application to apply the new configuration:
$ cd ~/aws-k8s-lab/kubernetes/
$ kustomize build base | kubectl apply -f -The Message Service is configured to return a message that uses the following template, configured in the message/src/main/resources/application.yml file:
demo:
greeting: Hello $name from $hostname with $version
version: "1.0"
spring:
application:
name: message
zipkin:
baseUrl: http://zipkin:9411/
sleuth:
sampler:
percentage: "1.0"
...There are several ways to update this configuration. We'll go through a couple of them, including:
- Environmental variable
- Command line argument
- and, Config Map
Environmental Variable
Spring applications can read the override configuration directly from an environmental variable. In this case, the environmental variable is defaulted to DEMO_GREETING. You can specify the environmental variable directly in the Deployment as well.
Edit message-patch.yaml
$ rm ~/aws-k8s-lab/kubernetes/base/message-patch.yaml
$ vi ~/aws-k8s-lab/kubernetes/base/message-patch.yamladd the environmental variable (you can fully replace the content of the file with this):
apiVersion: apps/v1
kind: Deployment
metadata:
name: message-service
spec:
template:
spec:
containers:
- name: message-service
env:
- name: DEMO_GREETING
value: Hello $name from environment!
resources:
requests:
cpu: 200m
memory: 256MiSave the file, and then redeploy the application to apply the new configuration:
$ cd ~/aws-k8s-lab/kubernetes/
$ kustomize build base | kubectl apply -f -Again, through the use of Deployments, it'll update all the replicas with the new configuration!
Wait 30 sec and go back to the frontend in the browser, add a new message and you should be able to see the greeting message changed.
Command Line Argument
Edit message-patch.yaml
$ rm ~/aws-k8s-lab/kubernetes/base/message-patch.yaml
$ vi ~/aws-k8s-lab/kubernetes/base/message-patch.yamladd a configuration via the command line arguments (you can fully replace the content of the file with this):
apiVersion: apps/v1
kind: Deployment
metadata:
name: message-service
spec:
template:
spec:
containers:
- name: message-service
command:
- "launcher"
args:
- "java"
- "-jar"
- "/workspace/message-0.0.1-SNAPSHOT.jar"
- --demo.greeting=Hello $name from args
resources:
requests:
cpu: 200m
memory: 256MiSave the file, and then redeploy the application to apply the new configuration:
$ cd ~/aws-k8s-lab/kubernetes/
$ kustomize build base | kubectl apply -f -Check the application and submit a name and message to see it is using the new greeting string (you might need to wait for up to 30-40 seconds for service to recreate).
Using ConfigMap
In this section, we'll use a ConfigMap to configure the application. You can store multiple text-based configuration files inside of a single ConfigMap configuration. In our example, we'll store Spring's application.yml into a ConfigMap entry.
First, update the application.yml file
$ rm ~/aws-k8s-lab/message/src/main/resources/application.yml
$ vi ~/aws-k8s-lab/message/src/main/resources/application.ymlReplace it with new configuration:
demo:
greeting: Hello $name from ConfigMap
version: "1.0"
spring:
application:
name: message
zipkin:
baseUrl: http://zipkin:9411/
sleuth:
sampler:
percentage: "1.0"
propagation-keys: x-request-id,x-ot-span-context
management:
server:
port: 9000
endpoints:
web:
exposure:
include: "*"Next, create a ConfigMap entry with this file:
$ cd ~/aws-k8s-lab/kubernetes/base
$ cp ~/aws-k8s-lab/message/src/main/resources/application.yml ~/aws-k8s-lab/kubernetes/base
$ kustomize edit add configmap greeting-config --disableNameSuffixHash --from-file=application.ymlThere are several ways to access the values in this ConfigMap:
- Mount the entries (in our case, application.yml) as a file.
- Access from the Kubernetes API (we won't cover this today).
Edit message-patch.yaml
$ rm ~/aws-k8s-lab/kubernetes/base/message-patch.yaml
$ vi ~/aws-k8s-lab/kubernetes/base/message-patch.yamladd volumes and volume mounts (you can fully replace the content of the file with this):
apiVersion: apps/v1
kind: Deployment
metadata:
name: message-service
spec:
template:
spec:
volumes:
- name: config-volume
configMap:
name: greeting-config
containers:
- name: message-service
command:
- "launcher"
args:
- "java"
- "-jar"
- "/workspace/message-0.0.1-SNAPSHOT.jar"
- --spring.config.location=/workspace/config/application.yml
volumeMounts:
- name: config-volume
mountPath: /workspace/config
resources:
requests:
cpu: 200m
memory: 256MiThis will make the configuration file available as the file /etc/config/application.yml and tell Spring Boot to use that file for configuration.
Save the file, and then redeploy the application to apply the new configuration:
$ cd ~/aws-k8s-lab/kubernetes/
$ kustomize build base | kubectl apply -f -Let's take a look inside the newly created entry:
$ kubectl edit configmap greeting-configYou'll see that the application.yml is now part of the YAML file.
Check the application to see it is using the new greeting string.
ConfigMap is great to store text-based configurations. Depending on your use cases, it may not be the best place to store your credentials (which sometimes may be a binary file rather than text). Secrets can be used to hold sensitive information, such as passwords, OAuth tokens, and SSH keys. Entries in Secrets are Base64 encoded. However, Secrets are not additionally encrypted by default when stored in Kubernetes.
In this section, we'll create a Secret that contains the MySQL username and password. We'll subsequently update both the MySQL Deployment and the Guestbook Service to refer to the same credentials.
First, let's create a Secret with username and password the command line:
$ cd ~/aws-k8s-lab/kubernetes/base
$ kustomize edit add secret mysql-secret --disableNameSuffixHash \
--from-literal=username=root --from-literal=password=yourpasswordIn the pods, you can access these values a couple of ways:
- Mount each entry as a file under a directory (similar to what we did with ConfigMap)
- Use Downward API to expose each entry as an Environmental Variable (which you can also do with ConfigMap).
Next, configure the Guestbook Service, by editing the Deployment and updating the Environmental Variables too.
Create a file guest-patch.yaml
$ vi ~/aws-k8s-lab/kubernetes/base/guest-patch.yamladd a couple of Environmental Variables (and remove the old ones for clearer experiment):
apiVersion: apps/v1
kind: Deployment
metadata:
name: guestbook-service
spec:
template:
spec:
containers:
- name: guestbook-service
env:
- name: SPRING_DATASOURCE_USERNAME
valueFrom:
secretKeyRef:
name: mysql-secret
key: username
- name: SPRING_DATASOURCE_PASSWORD
valueFrom:
secretKeyRef:
name: mysql-secret
key: password
- name: DB_HOST
value: mysql
- name: DB_USER
$patch: delete
- name: DB_PASS
$patch: deleteNext, use Kustomize to add this patch to our Guestbook Service manifest:
$ cd ~/aws-k8s-lab/kubernetes/base/
$ kustomize edit add patch --path guest-patch.yamlRedeploy the application to apply the new configuration:
$ cd ~/aws-k8s-lab/kubernetes/
$ kustomize build base | kubectl apply -f -Once the deployment is completed, check that the application is still working.
If you look into the newly created Secret, you'll see that the values are Base64 encoded:
$ kubectl edit secret mysql-secret
apiVersion: v1
data:
password: eW91cnBhc3N3b3Jk
username: cm9vdA==
kind: Secret
...As our database is not managed by kustomize, we can manually edit the stateful set manifest. Edit the file mysql-stateful.yaml
$ vi ~/aws-k8s-lab/kubernetes/mysql-stateful.yamland find the environment variables section that looks like this:
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: mysql
...
spec:
...
template:
...
spec:
containers:
- name: mysql
...
env:
- name: MYSQL_ROOT_PASSWORD
# change this
value: yourpassword
- name: MYSQL_DATABASE
value: app
...Edit it to reference the same secret:
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: mysql
...
spec:
...
template:
...
spec:
containers:
- name: mysql
...
env:
- name: MYSQL_ROOT_PASSWORD
valueFrom:
secretKeyRef:
name: mysql-secret
key: password
- name: MYSQL_DATABASE
value: app
...We can deploy MySQL as a StatefulSet:
$ cd ~/aws-k8s-lab/kubernetes/
$ kubectl apply -f mysql-stateful.yamlWait a minute for MySQL to restart with the password from secret and check if the application is working.
Google Kubernetes Engine has built-in Horizontal Pod Autoscaling based on CPU utilization (and custom metrics!). We will cover autoscaling based on CPU utilization in this lab.
To set up horizontal auto scaling is extremely simple:
$ kubectl autoscale deployment message-service --min=2 --max=10 --cpu-percent=80Behind the scenes, Kubernetes will periodically (by default, every 30 seconds) collect CPU utilization and determine the number of pods needed.
You can see the current status of the autoscaler by using the describe command:
$ kubectl describe hpa message-serviceSo far, the lab has been showing how to run long running serving processes. What if you need to run a one-time job, such as a batch process, or simply leveraging the cluster to compute a result (like computing digits of Pi)? You shouldn't use Replica Sets and Deployments to run a job that is expected to exit once it completes the computation (otherwise, upon exit, it'll be restarted again!).
Kubernetes supports running these run-once jobs, which it'll create one or more pods and ensures that a specified number of them successfully terminate. When a specified number of successful completions is reached, the job itself is complete. In many cases, you'll have run a job that only needs to be completed once.
Let's create a Job to generate the load for our HPA.
To create a simple job paste the following into console:
$ cat <<EOF | kubectl apply -f -
apiVersion: batch/v1
kind: Job
metadata:
name: job1
spec:
backoffLimit: 4
template:
spec:
containers:
- command:
- /bin/sh
- '-c'
- ab -n 50000 -c 1000 http://message-service:80/hello/test/
image: 'httpd:alpine'
name: scale-deployment
restartPolicy: OnFailure
EOFYou'll be able to see the status of the job via the command line:
$ kubectl describe jobs job1Then, you can use kubectl logs to retrieve the job output:
$ export JOB_POD=$(kubectl get pods -l job-name=job1 -o jsonpath='{.items[0].metadata.name}')
$ kubectl logs $JOB_PODCheck the Pods, you should see the Message Service is being autoscaled. Some of them can be in Pending state, as there might not be enough resources in the cluster. Retry command a few times as there's a delay before the pods are actually scaled after the loa dis increased.
$ kubectl get podsMonitoring in Kubernetes
Traditionally, Java applications are monitored via JMX metrics, which may have metrics on thread count, heap usage, etc. In the Cloud Native world where you monitor more than just Java stack, you need to use more generic metrics formats, such as Prometheus.
Prometheus's main features are:
- a multi-dimensional data model with time series data identified by metric name and key/value pairs
- PromQL, a flexible query language to leverage this dimensionality
- no reliance on distributed storage; single server nodes are autonomous
- time series collection happens via a pull model over HTTP
- pushing time series is supported via an intermediary gateway
- targets are discovered via service discovery or static configuration
- multiple modes of graphing and dashboarding support
Spring Boot can expose metrics information via Spring Boot Actuator, and with the combination of Micrometer, it can expose all the metrics with the Prometheus format. It is easy to add Prometheus support.
If you are not using Spring Boot, you can expose JMX metrics via Prometheus by using a Prometheus JMX Exporter agent.
Our application is already configured for exporting metrics to Prometheus. Let's check it out!
Find the pod name for one of the instances of Message, UI or Guestbook services.
$ kubectl get pods -l 'app in (message-service,ui,guestbook-service)'
NAME READY STATUS RESTARTS AGE
guestbook-service-xxxxxxxxxx-zzzzz 1/1 Running 0 20m
message-service-xxxxxxxxxx-zzzzz 1/1 Running 0 15m
ui-xxxxxxxxxx-zzzzz 1/1 Running 0 5mEstablish a port forward to one of the pods, for example UI:
$ kubectl port-forward ui-... 9000:9000In a new Cloud Shell tab, use curl to access the Prometheus endpoint.
$ curl http://localhost:9000/actuator/prometheus
Output:
# HELP jvm_threads_daemon_threads The current number of live daemon threads
# TYPE jvm_threads_daemon_threads gauge
jvm_threads_daemon_threads 31.0
# HELP zipkin_reporter_messages_dropped_total
# TYPE zipkin_reporter_messages_dropped_total counter
zipkin_reporter_messages_dropped_total{cause="ResourceAccessException",} 69.0
# HELP zipkin_reporter_queue_bytes Total size of all encoded spans queued for reporting
# TYPE zipkin_reporter_queue_bytes gauge
zipkin_reporter_queue_bytes 0.0
...Some of these metrics, like jvm_memory_committed_bytes, have multiple dimensions (area and id). These dimensions will also be filterable/groupable within Prometheus.
Close the second terminal tab and in the first tab stop the port forwarding with Ctrl+C.
We will be using the Prometheus Operator, that provides Kubernetes native deployment and management of Prometheus and related monitoring components.
Install a quickstart Prometheus operator:
$ kubectl apply -f https://github.com/prometheus-operator/prometheus-operator/releases/download/v0.56.2/bundle.yaml \
--force-conflicts=true \
--server-sideProvision Prometheus using the Prometheus Operator.
$ cd ~/aws-k8s-lab/kubernetes/
$ kubectl apply -f prometheus.yamlNext, we'll use the simplest kind of monitoring configuration - PodMonitor.
$ cd ~/aws-k8s-lab/kubernetes/
$ kubectl apply -f pod-monitor.yamlLet's validate Prometheus is running properly and scraping the data. Expose it using a LoadBalancer service.
$ cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: Service
metadata:
name: prometheus-lb
spec:
type: LoadBalancer
ports:
- name: web
port: 9090
protocol: TCP
targetPort: web
selector:
prometheus: prometheus
EOFGet the address and open it in your browser:
$ export PROMETHEUS=`kubectl get svc prometheus-lb -n default -o=jsonpath={.status.loadBalancer.ingress[0].hostname}`
$ echo http://${PROMETHEUS}:9090In the Prometheus console, select Status → Targets.
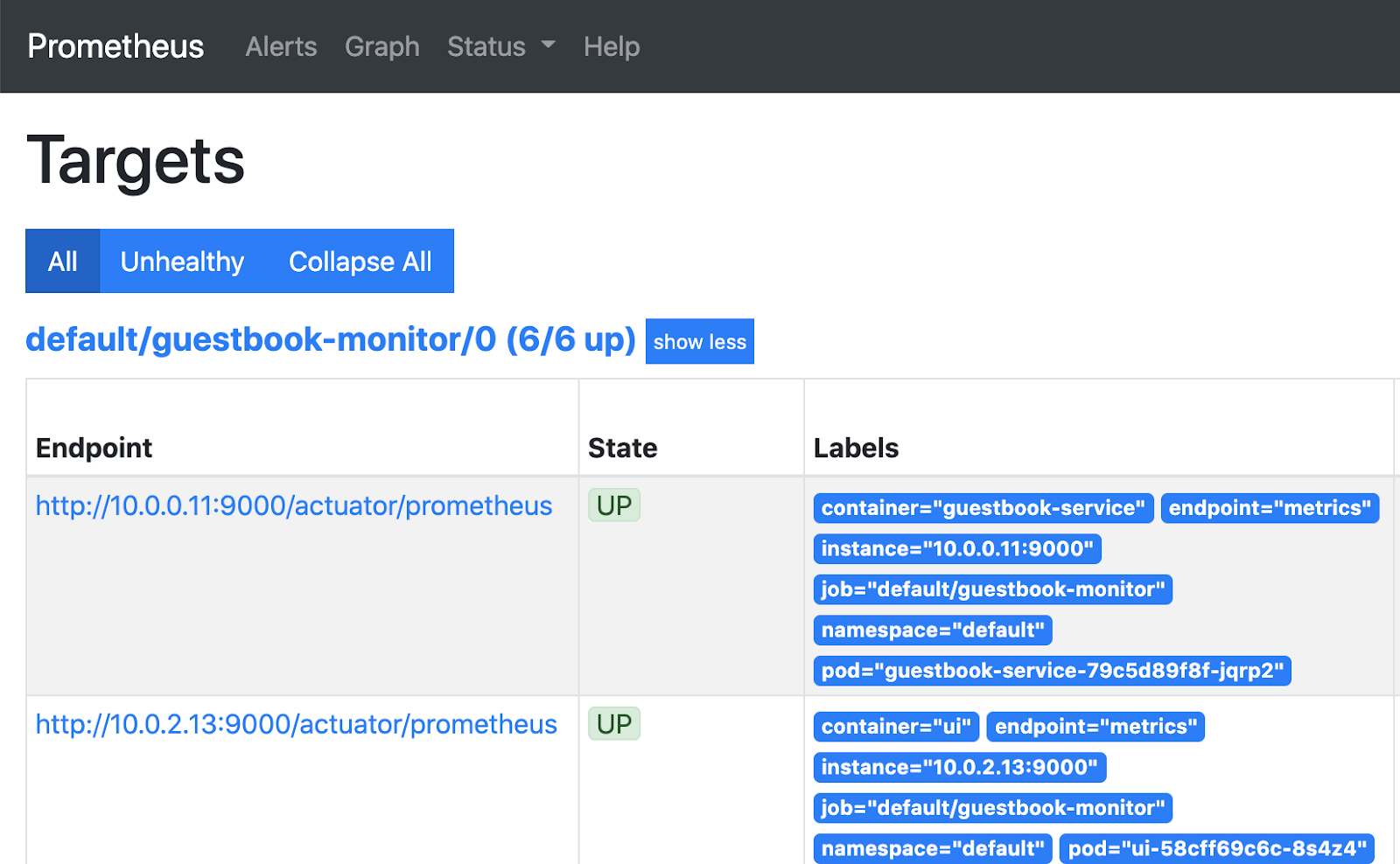
Observe that there are 6 targets (pods) being scrapped for metrics.
Explore the metrics in Prometheus
Navigate to Graph.
In the Expression field enter jvm_memory_used_bytes and press Execute.
In the Console tab below you should see all available metrics and their dimensions.
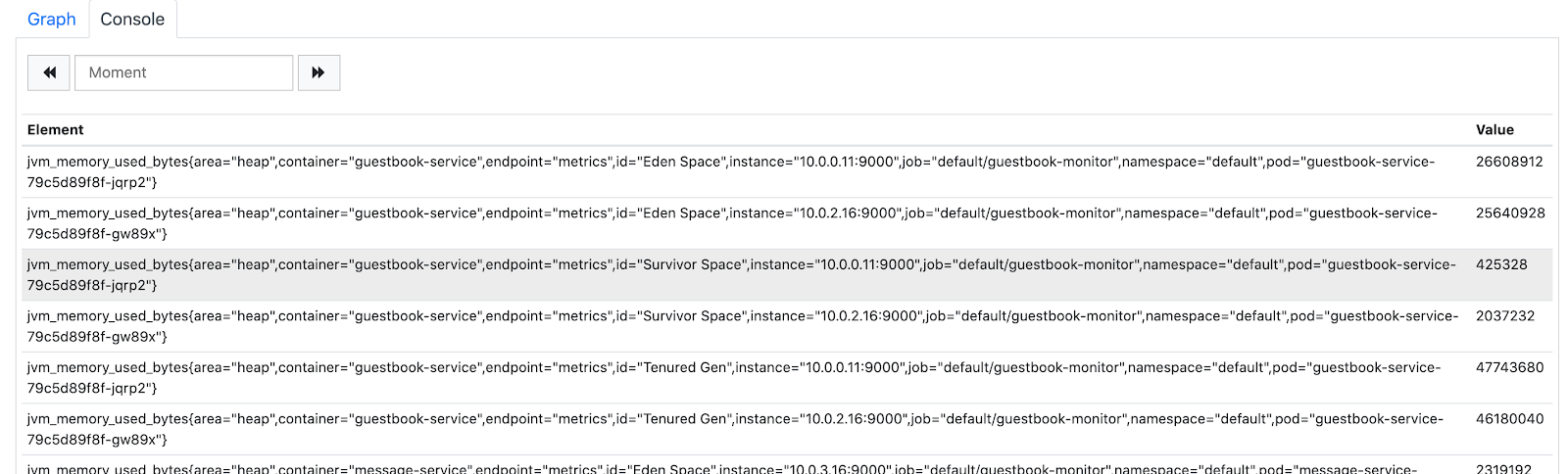
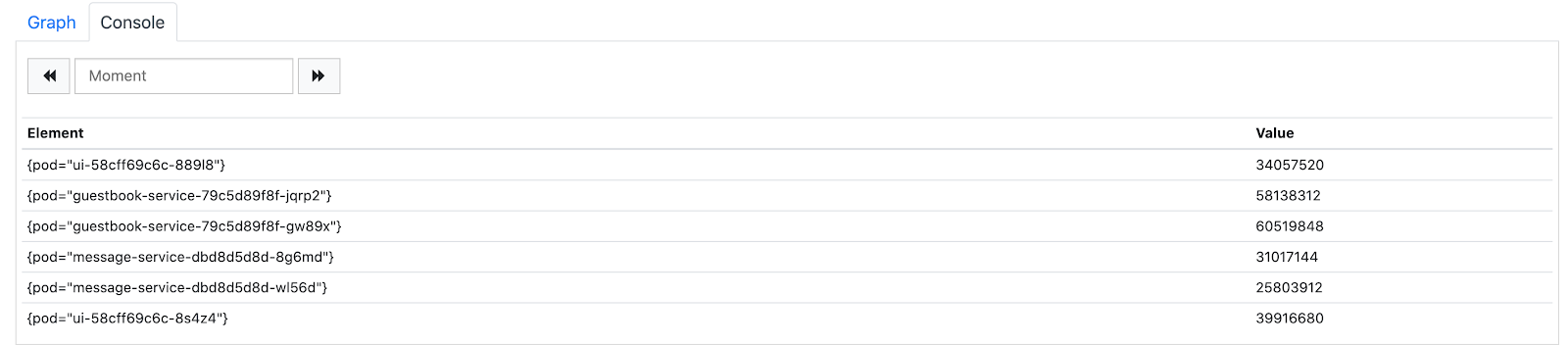
It doesn't give us much information. Let's modify the query to filter by area dimension and sum it by pod dimension.
Enter the following in the Expression and press execute.
sum by (pod) (jvm_memory_used_bytes{area="heap"})This will give us the total memory our Java applications are using per pod.
Click the Graph tab to see a graph of our memory usage (check the stacked box to make it prettier).
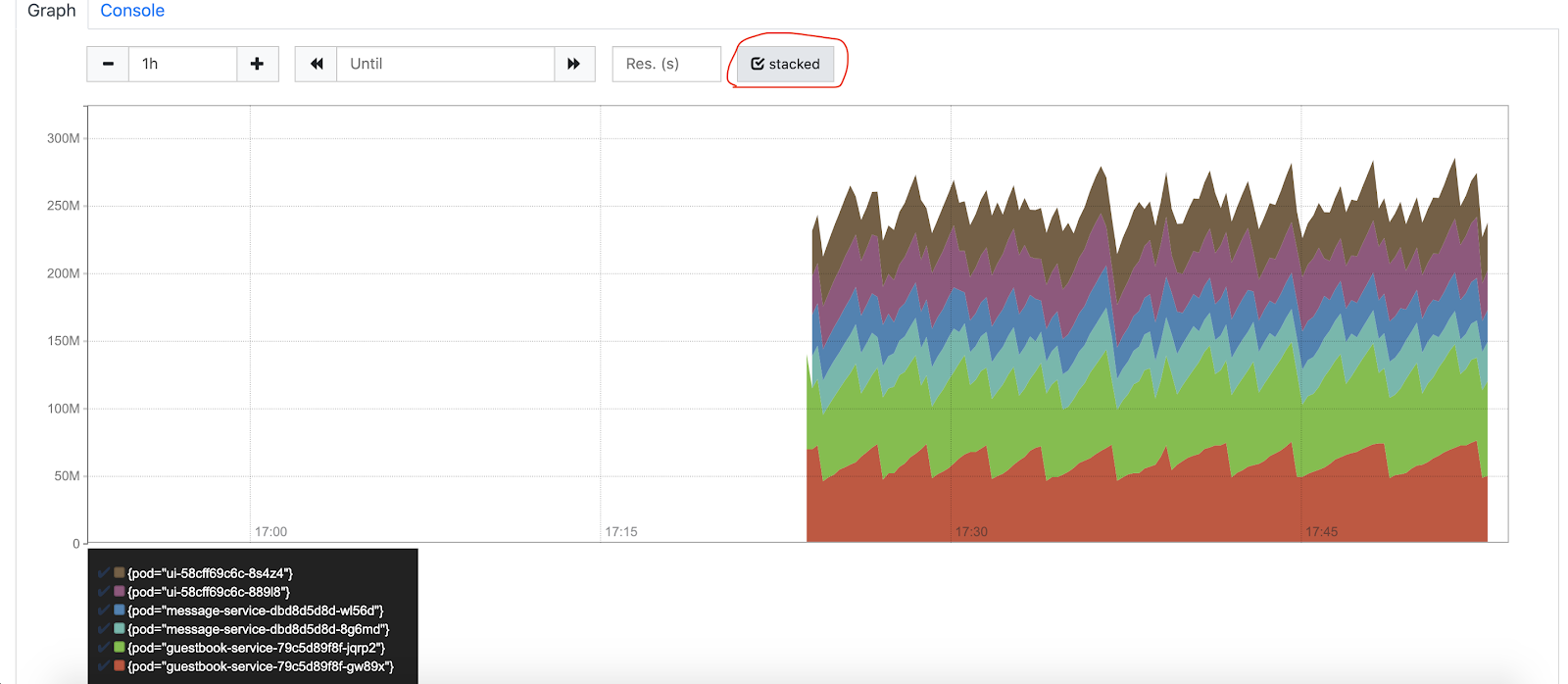
Prometheus is good for scrapping metrics, but it is not great for visualization. You might need to add Grafana for real use cases.
You can play with other metrics and move to the next step.
Observability in a Microservices architecture
Kubernetes has become the de-facto orchestrator for microservices infrastructure and deployment. The ecosystem is extremely rich and one of the fastest growing in the open-source community.
Distributed tracing enables capturing requests and building a view of the entire chain of calls made all the way from user requests to interactions between hundreds of services. It also enables instrumentation of application latency (how long each request took), tracking the lifecycle of network calls (HTTP, RPC, etc) and also identifies performance issues by getting visibility on bottlenecks.
As an example of distributed tracing we will use an already setup integration of Spring with Zipkin.
Deploy Zipkin deployment and service:
$ cd ~/aws-k8s-lab/kubernetes/
$ kubectl apply -f zipkin-deployment.yaml -f zipkin-service.yamlGet the address and open it in your browser:
$ export ZIPKIN=`kubectl get svc zipkin -n default -o=jsonpath={.status.loadBalancer.ingress[0].hostname}`
$ echo http://${ZIPKIN}:9411Go back to our Guestbook UI and refresh it a couple of times and post a new message.
In Zipkin, click Dependencies.

Then, make sure you select the right date and press the search button. You should see our services connected with each other.
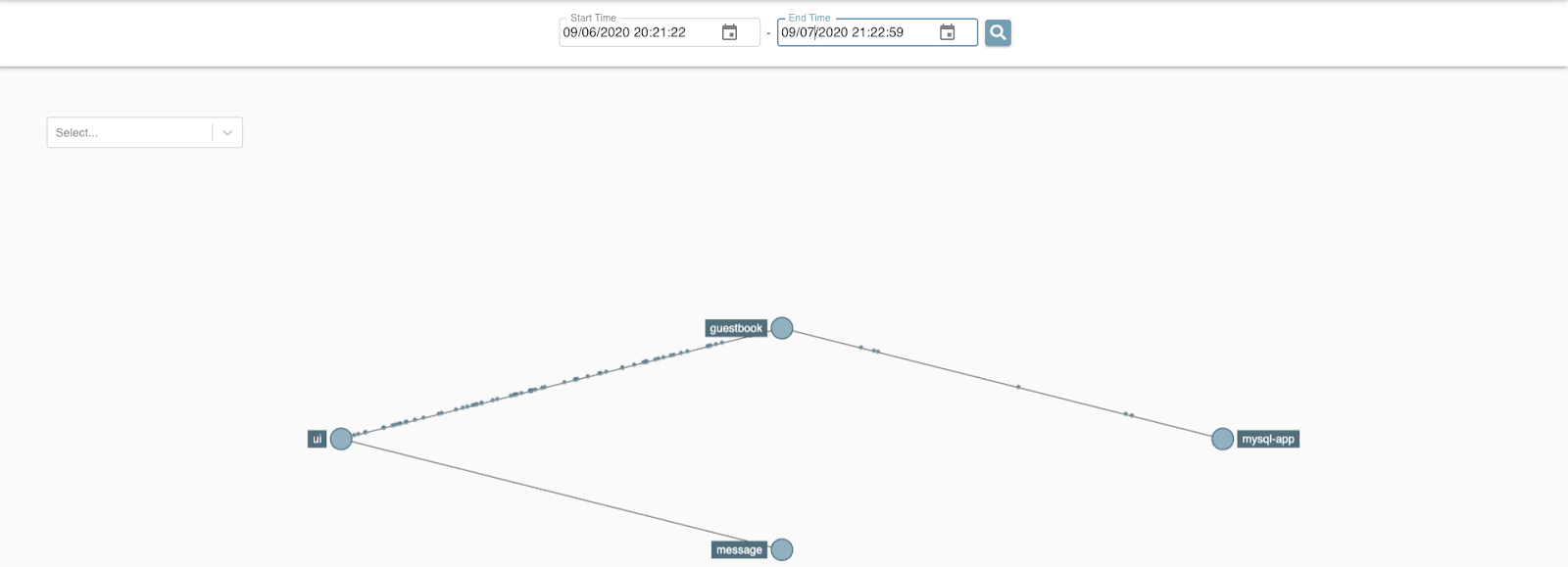
Click the UI to see which services it is connected with.
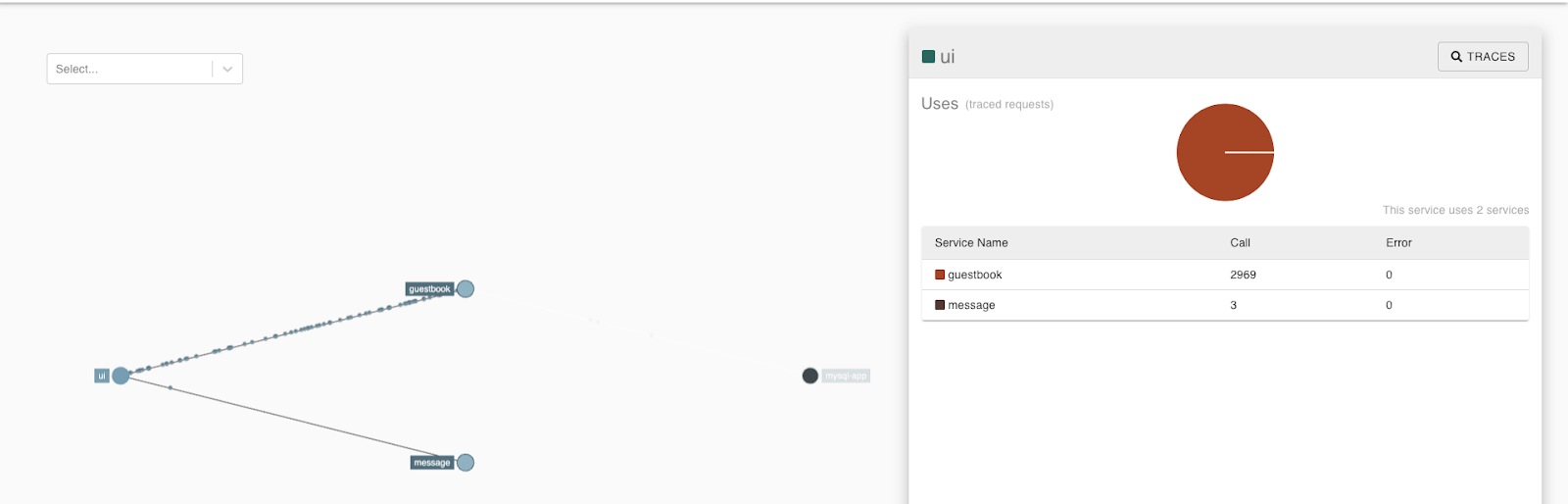
Then, click the Traces button in the right corner.
Make sure the ui service is selected and press the Run Query button.

Select any of the available traces and click Show.
You should see the trace details.
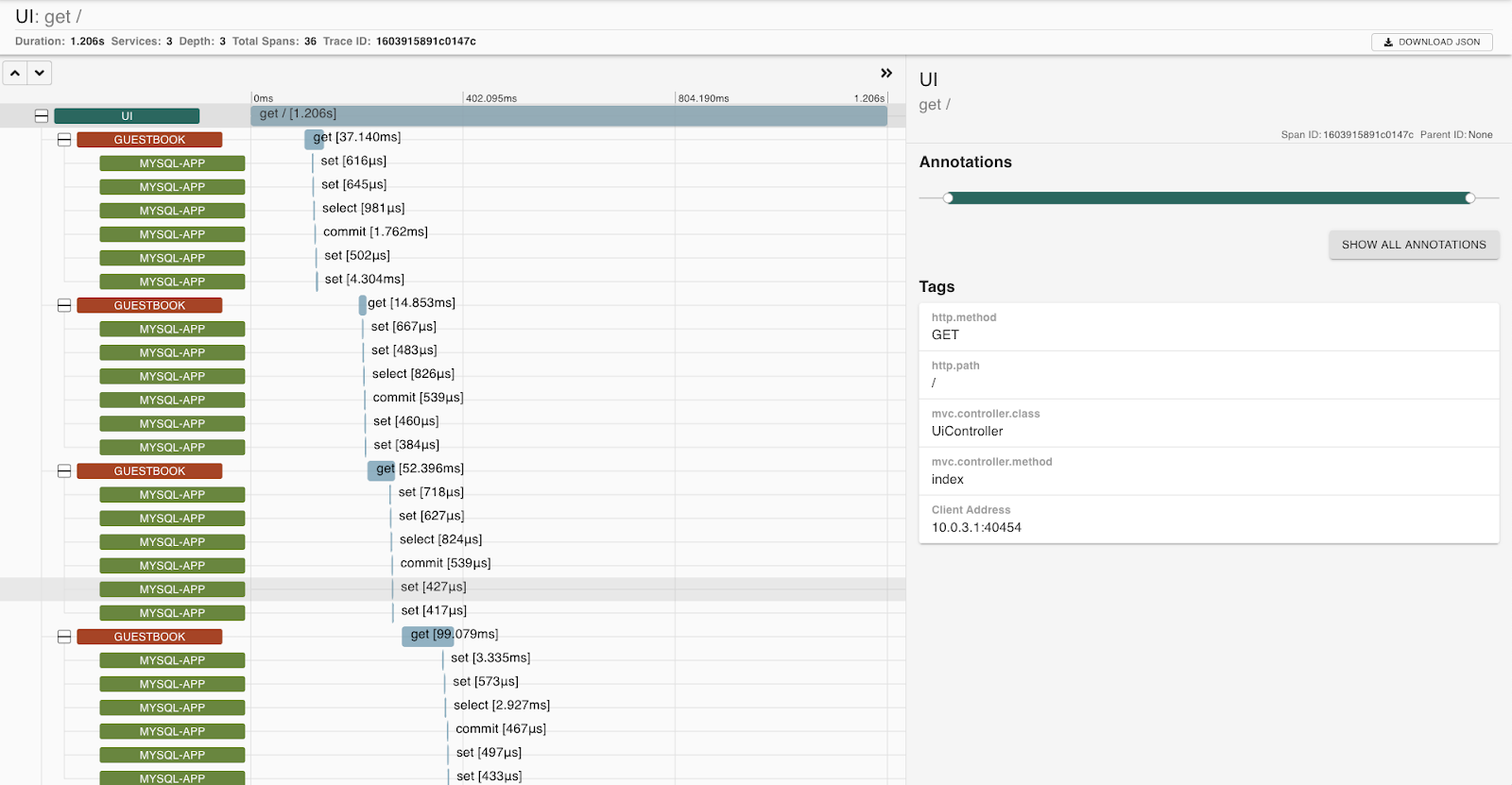
To delete the Ingress controller and services to terminate the LoadBalancers:
$ kubectl delete -f https://raw.githubusercontent.com/kubernetes/ingress-nginx/controller-v1.7.0/deploy/static/provider/aws/deploy.yaml
$ kubectl delete svc prometheus-lb
$ kubectl delete svc zipkinTo delete the cluster execute the following command.
$ kops delete cluster --name $NAME --yesWhen the cluster is removed - delete the bucket.
$ aws s3api delete-bucket \
--bucket ${STATE_BUCKET} \
--region ${REGION}Delete the ECR repositories:
for name in "ui" "message" "guestbook" "kpack"
do
/usr/local/bin/aws ecr delete-repository \
--repository-name "${REPO_PREFIX}"-"${name}" \
--force
doneThank you! :)