
Last Updated: 2023-02-12
Kubernetes
Kubernetes is an open source project (available on kubernetes.io) which can run on many different environments, from laptops to high-availability multi-node clusters, from public clouds to on-premise deployments, from virtual machines to bare metal.
Kubernetes operations (kops) acts as a kubectl for clusters.
kops helps you create, destroy, upgrade and maintain production-grade, highly available, Kubernetes clusters from the command line. AWS (Amazon Web Services) is currently officially supported, with GCE and OpenStack in beta support.
What you'll build
In this codelab, you're going to deploy a Kubernetes cluster in AWS using Kops.
What you'll need
- A recent version of your favorite Web Browser
- Basics of BASH
- AWS Account
Before you can use Kubernetes to deploy your application, you need a cluster of machines to deploy them to. The cluster abstracts the details of the underlying machines you deploy to the cluster.
Machines can later be added, removed, or rebooted and containers are automatically distributed or re-distributed across whatever machines are available in the cluster. Machines within a cluster can be set to autoscale up or down to meet demand. Machines can be located in different zones for high availability.
Open Cloud Shell
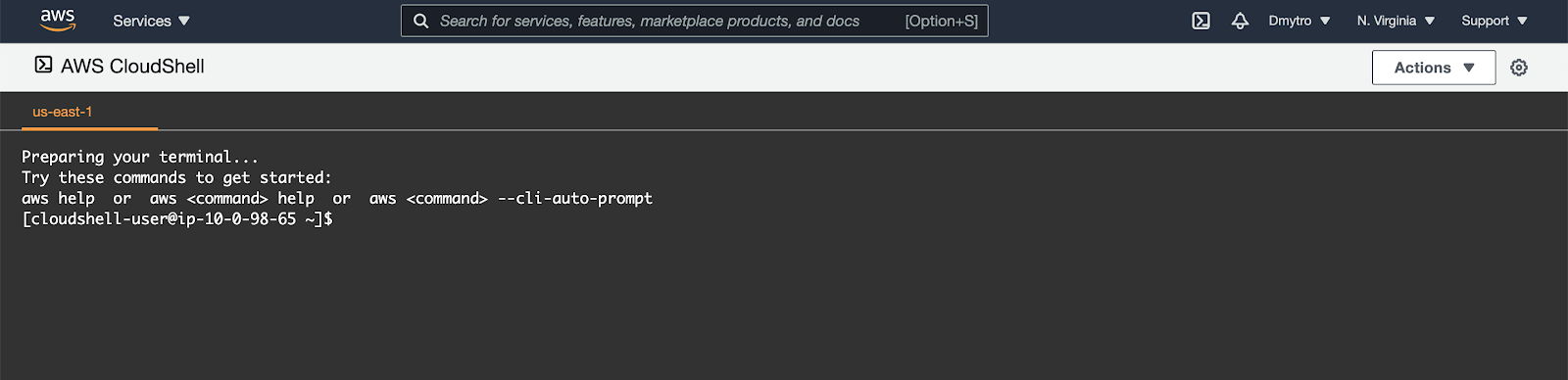
You will do some of the work from the Amazon Cloud Shell, a command line environment running in the Cloud. This virtual machine is loaded with all the development tools you'll need (aws cli, python) and offers a persistent 1GB home directory and runs in AWS, greatly enhancing network performance and authentication. Open the Amazon Cloud Shell by clicking on the icon on the top right of the screen:

You should see the shell prompt open in the new tab:
Initial setup
Before creating a cluster, you must install and configure the following tools:
kubectl– A command line tool for working with Kubernetes clusters.kops– A command line tool for Kubernetes clusters in the AWS Cloud.
To install kops, run the following:
$ curl -Lo kops https://github.com/kubernetes/kops/releases/download/$(curl -s https://api.github.com/repos/kubernetes/kops/releases/latest | grep tag_name | cut -d '"' -f 4)/kops-linux-amd64
$ chmod +x ./kops
$ sudo mv ./kops /usr/local/bin/Confirm the kops command works:
$ kops versionTo install kubectl, run the following:
$ curl -Lo kubectl https://storage.googleapis.com/kubernetes-release/release/$(curl -s https://storage.googleapis.com/kubernetes-release/release/stable.txt)/bin/linux/amd64/kubectl
$ chmod +x ./kubectl
$ sudo mv ./kubectl /usr/local/bin/kubectlkops needs a state store to hold the configuration for your clusters. The simplest configuration for AWS is to store it in a S3 bucket in the same account, so that's how we'll start.
Create an empty bucket, replacing YOUR_NAME with your name 😁:
$ export REGION=us-east-1
$ export STATE_BUCKET=YOUR_NAME-state-store
# Create the bucket using awscli
$ aws s3api create-bucket \
--bucket ${STATE_BUCKET} \
--region ${REGION}If the name is taken and you receive an error - change the name and try again.
Next, rather than typing the different command argument every time, it's much easier to export the KOPS_STATE_STORE and NAME variables to previously setup bucket name and a cluster name that ends with .k8s.local, for example:
$ export NAME="mycoolcluster.k8s.local" #SHOULD END WITH .k8s.local
$ export KOPS_STATE_STORE="s3://${STATE_BUCKET}"After that - generate a dummy SSH key for kops to use:
$ ssh-keygen -b 2048 -t rsa -f ${HOME}/.ssh/id_rsa -q -N ""Option 1: Create Cluster without Metrics Server
Now you are ready to create the cluster. We're going to create a production ready high availability cluster with 3 masters and 3 nodes (3 node autoscaling groups with 1 node each, actually):
$ kops create cluster \
--name ${NAME} \
--state ${KOPS_STATE_STORE} \
--node-count 3 \
--master-count=3 \
--zones us-east-1a,us-east-1b,us-east-1c \
--master-zones us-east-1a,us-east-1b,us-east-1c \
--node-size t2.small \
--master-size t2.medium \
--master-volume-size=20 \
--node-volume-size=20 \
--networking flannel \
--cloud-labels "ita_group=devops"When cluster configuration is ready, edit it:
$ kops edit cluster ${NAME}In the editor - find the iam section at the end of the spec that looks like this:
...
spec:
...
iam:
allowContainerRegistry: true
legacy: false
...Edit it so it looks like the next snippet:
...
spec:
...
iam:
allowContainerRegistry: true
legacy: false
permissionsBoundary: arn:aws:iam::390349559410:policy/CustomPowerUserBound
...After saving the document, run the following set of commands:
$ kops update cluster ${NAME} --yes --adminWait 5-10 minutes till the cluster is ready. You can check its state by periodically running validate:
$ kops validate cluster --wait 10m
....
Your cluster mycoolcluster.k8s.local is readyOption 2: Create Cluster with Metrics Server
Metrics Server is a scalable, efficient source of container resource metrics for Kubernetes built-in autoscaling pipelines.
Metrics Server collects resource metrics from Kubelets and exposes them in Kubernetes apiserver through Metrics API for use by Horizontal Pod Autoscaler and Vertical Pod Autoscaler. Metrics API can also be accessed by kubectl top, making it easier to debug autoscaling pipelines.
Metrics Server is not meant for non-autoscaling purposes. For example, don't use it to forward metrics to monitoring solutions, or as a source of monitoring solution metrics.
Metrics Server offers:
- A single deployment that works on most clusters (see Requirements)
- Scalable support up to 5,000 node clusters
- Resource efficiency: Metrics Server uses 0.5m core of CPU and 4 MB of memory per node
Now you are ready to create the cluster. We're going to create a production ready high availability cluster with 3 masters and 3 nodes (3 node autoscaling groups with 1 node each, actually):
$ kops create cluster \
--name ${NAME} \
--state ${KOPS_STATE_STORE} \
--node-count 3 \
--master-count=3 \
--zones us-east-1a,us-east-1b,us-east-1c \
--master-zones us-east-1a,us-east-1b,us-east-1c \
--node-size t2.small \
--master-size t2.medium \
--master-volume-size=20 \
--node-volume-size=20 \
--networking flannel \
--cloud-labels "ita_group=devops"When cluster configuration is ready, edit it:
$ kops edit cluster ${NAME}In the editor - find the start of spec that looks like this:
...
spec:
api:
loadBalancer:
class: Classic
type: Public
...Edit it so it looks like the next snippet:
...
spec:
certManager:
enabled: true
metricsServer:
enabled: true
insecure: false
api:
loadBalancer:
class: Classic
type: Public
...Next, find the iam section at the end of the spec that looks like this:
...
spec:
...
iam:
allowContainerRegistry: true
legacy: false
...Edit it so it looks like the next snippet:
...
spec:
...
iam:
allowContainerRegistry: true
legacy: false
permissionsBoundary: arn:aws:iam::390349559410:policy/CustomPowerUserBound
...After saving the document, run the following set of commands:
$ kops update cluster ${NAME} --yes --adminWait 5-10 minutes till the cluster is ready. You can check its state by periodically running validate:
$ kops validate cluster --wait 10m
....
Your cluster mycoolcluster.k8s.local is readyKubernetes Dashboard is a general purpose, web-based UI for Kubernetes clusters. It allows users to manage applications running in the cluster and troubleshoot them, as well as manage the cluster itself.
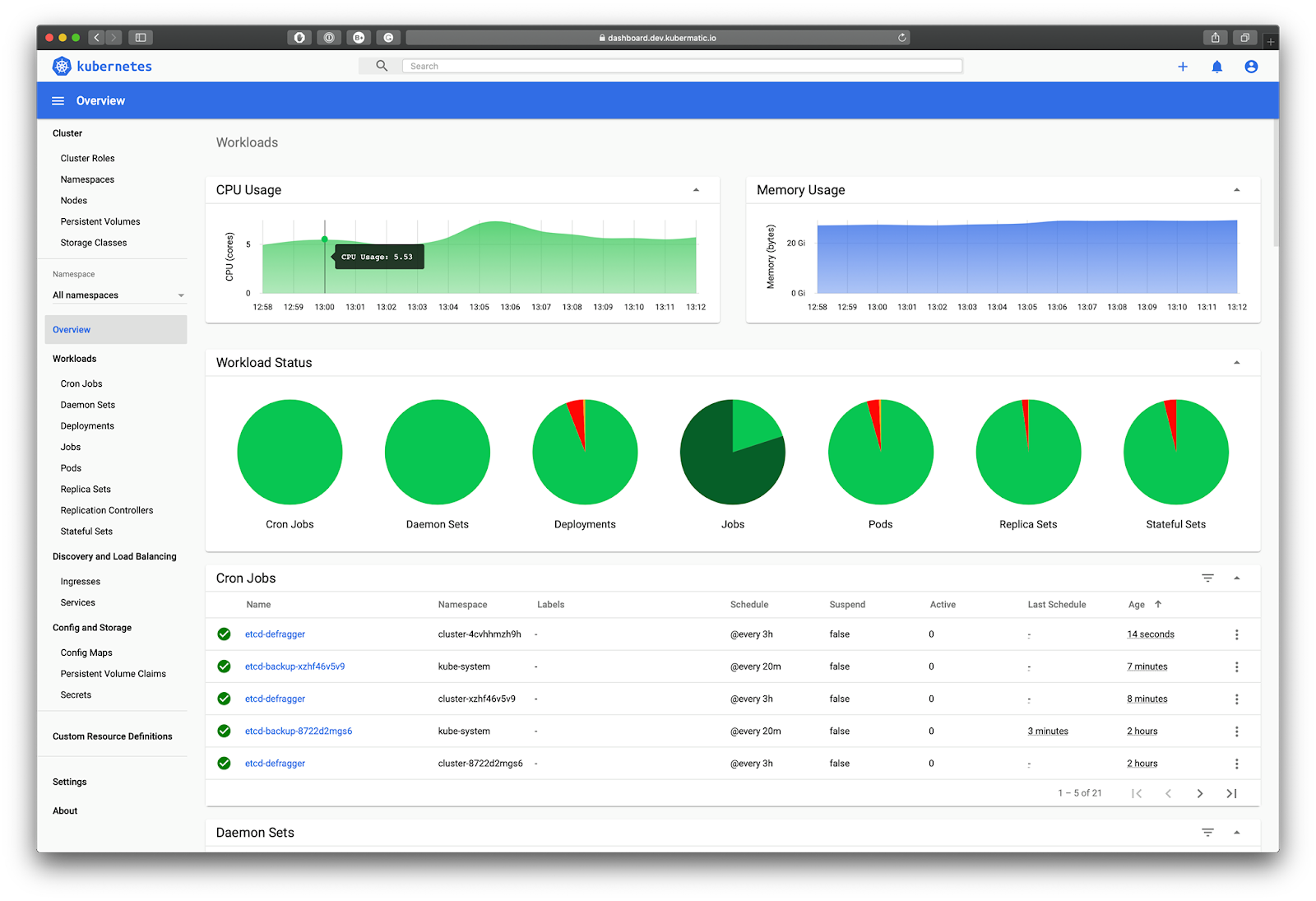
To install the dashboard in your cluster run the following commands.
First, make sure that you are using your cluster and create dashboard resources.
$ kubectl config use-context ${NAME}
$ kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/v2.7.0/aio/deploy/recommended.yamlNext, create an admin service account to access the dashboard:
$ cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: ServiceAccount
metadata:
name: admin-user
namespace: kubernetes-dashboard
---
apiVersion: v1
kind: Secret
metadata:
name: admin-user
namespace: kubernetes-dashboard
annotations:
kubernetes.io/service-account.name: admin-user
type: kubernetes.io/service-account-token
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: admin-user
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: admin-user
namespace: kubernetes-dashboard
EOFFinally, run the following command.
$ kubectl -n kubernetes-dashboard get secret $(kubectl -n kubernetes-dashboard get secret |\
grep admin-user | awk '{print $1}') -o=jsonpath="{.data.token}" |\
base64 -d | xargs echo
# Output is a long JWT token string of your Admin accountExposing the dashboard
Install a Kubernetes supported NGINX Controller that can work with AWS LoadBalancers.
$ kubectl apply -f https://raw.githubusercontent.com/kubernetes/ingress-nginx/controller-v1.2.0/deploy/static/provider/aws/deploy.yamlNext, create the Ingress resource to expose the dashboard (you might need to wait for 1-2 minutes before running the next command):
$ cat <<EOF | kubectl apply -f -
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: dashboard-ingress
namespace: kubernetes-dashboard
annotations:
kubernetes.io/ingress.class: nginx
nginx.ingress.kubernetes.io/rewrite-target: /
nginx.ingress.kubernetes.io/backend-protocol: "HTTPS"
nginx.ingress.kubernetes.io/ssl-passthrough: "true"
spec:
rules:
- http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: kubernetes-dashboard
port:
number: 443
EOFFinally, get the address of the LoadBalancer:
$ export DASH_URL=`kubectl get svc ingress-nginx-controller -n ingress-nginx -o=jsonpath='{.status.loadBalancer.ingress[0].hostname}'`
$ echo https://${DASH_URL}Copy the URL printed in your shell and paste it in your browser.
When you reach the login page - paste the token from the previous section to log in.
Create Kubernetes Deployment
Enter the following command to run your Kubernetes deployment:
$ cat <<EOF | kubectl create -f -
apiVersion: apps/v1
kind: Deployment
metadata:
name: devops-deployment
labels:
app: devops
tier: frontend
spec:
replicas: 3
selector:
matchLabels:
app: devops
tier: frontend
template:
metadata:
labels:
app: devops
tier: frontend
spec:
containers:
- name: devops-demo
image: kennethreitz/httpbin
ports:
- containerPort: 80
EOFEnter the following command to see if you have any instances of your application running.
$ kubectl get podsRun the command a few times until all the pods are running.
Enter the following to see the deployments.
$ kubectl get deploymentsNote the name of the deployment. This was specified in the configuration file.
Enter the following to see the details of your deployment.
$ kubectl describe deployments devops-deploymentIn the Web Dashboard go to Workloads → Pods.
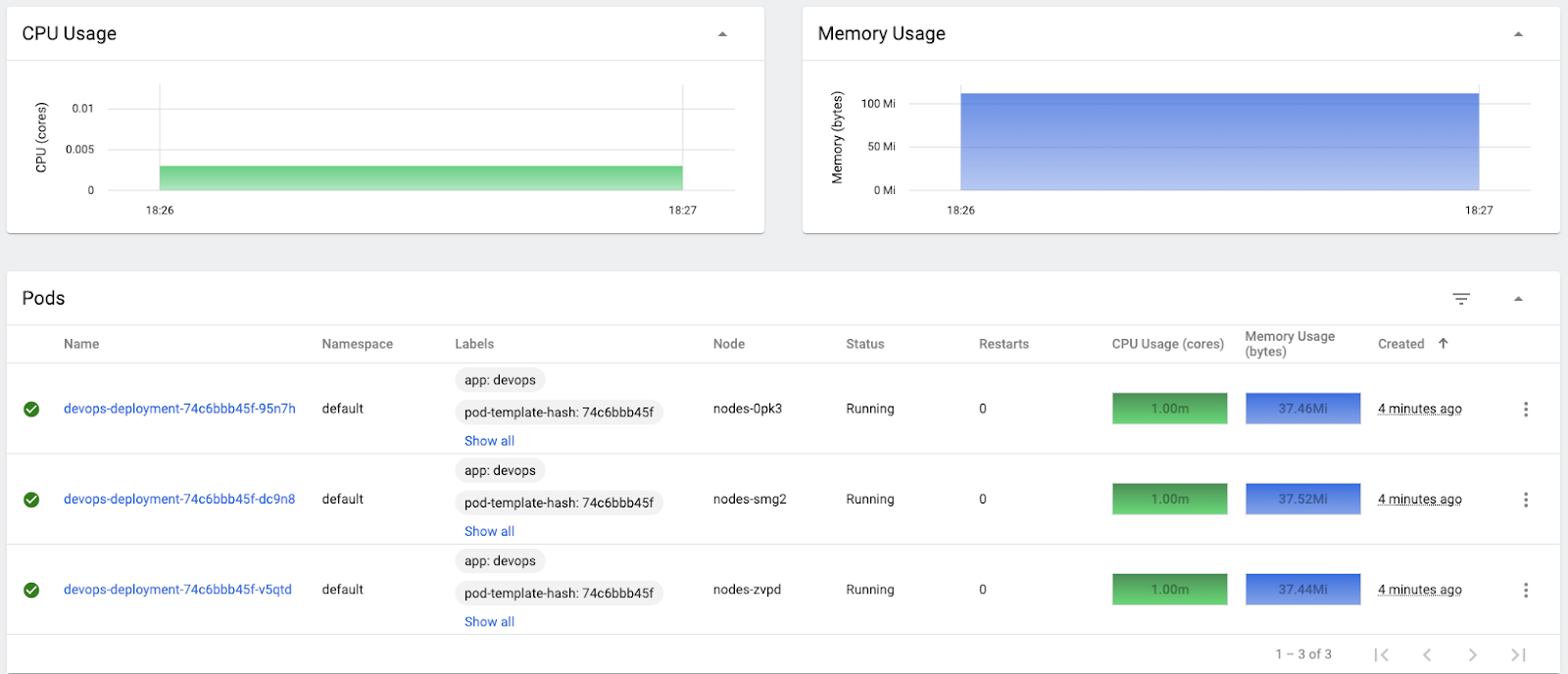
If you have enabled Metrics Server, then in about 2-3 minutes you should see CPU & Memory usages of your pods.
Expose the Deployment
You have application instances, but can't yet access them with a browser because they are not exposed outside of Kubernetes. Expose the application and create a load balancer with the following command.
$ kubectl expose deployment devops-deployment --port=80 --target-port=80 --type=LoadBalancerYou need the address of the load balancer. Type the following command to get it.
$ kubectl get servicesOnce you have an external IP address, curl the application.
$ export APP_URL=`kubectl get svc devops-deployment -o=jsonpath={.status.loadBalancer.ingress[0].hostname}`
$ curl http://${APP_URL}/headersScale the Deployment
Let's scale up to 10 instances.
$ kubectl scale deployment devops-deployment --replicas=10After the command completes, type kubectl get pods to see if it worked. You might have to run the command a few times before all 10 are running.
Let's scale back to 3 instances.
$ kubectl scale deployment devops-deployment --replicas=3After the command completes, type kubectl get pods to see if it worked. You might have to run the command a few times.
Let's create a Horizontal Pod Autoscaler (HPA). It will allow us to scale the instances automatically depending on load.
Type the following command.
$ kubectl autoscale deployment devops-deployment --min=5 --max=10 --cpu-percent=60Wait a little while and type kubectl get pods again. The autoscaler will create two more pods. As before, you might have to wait a little while and run the command a couple times.
Let's try to generate some load. First install Apache. Apache includes a testing tool called ApacheBench. It allows us to simulate load. If we send enough requests, we should get the pods to autoscale.
$ sudo yum install httpd-tools -yThen run the following command (probably multiple times) to get enough load. Make sure you have the ending slash! It will generate 500k requests, with 1k batches.
$ export APP_URL=`kubectl get svc devops-deployment -o=jsonpath={.status.loadBalancer.ingress[0].hostname}`
$ ab -n 500000 -c 1000 http://${APP_URL}/Run kubectl get pods after running ApacheBench to see if pods do scale.
In the Web Dashboard you should see a huge CPU & memory spike reflecting the increased load and more pods being created.
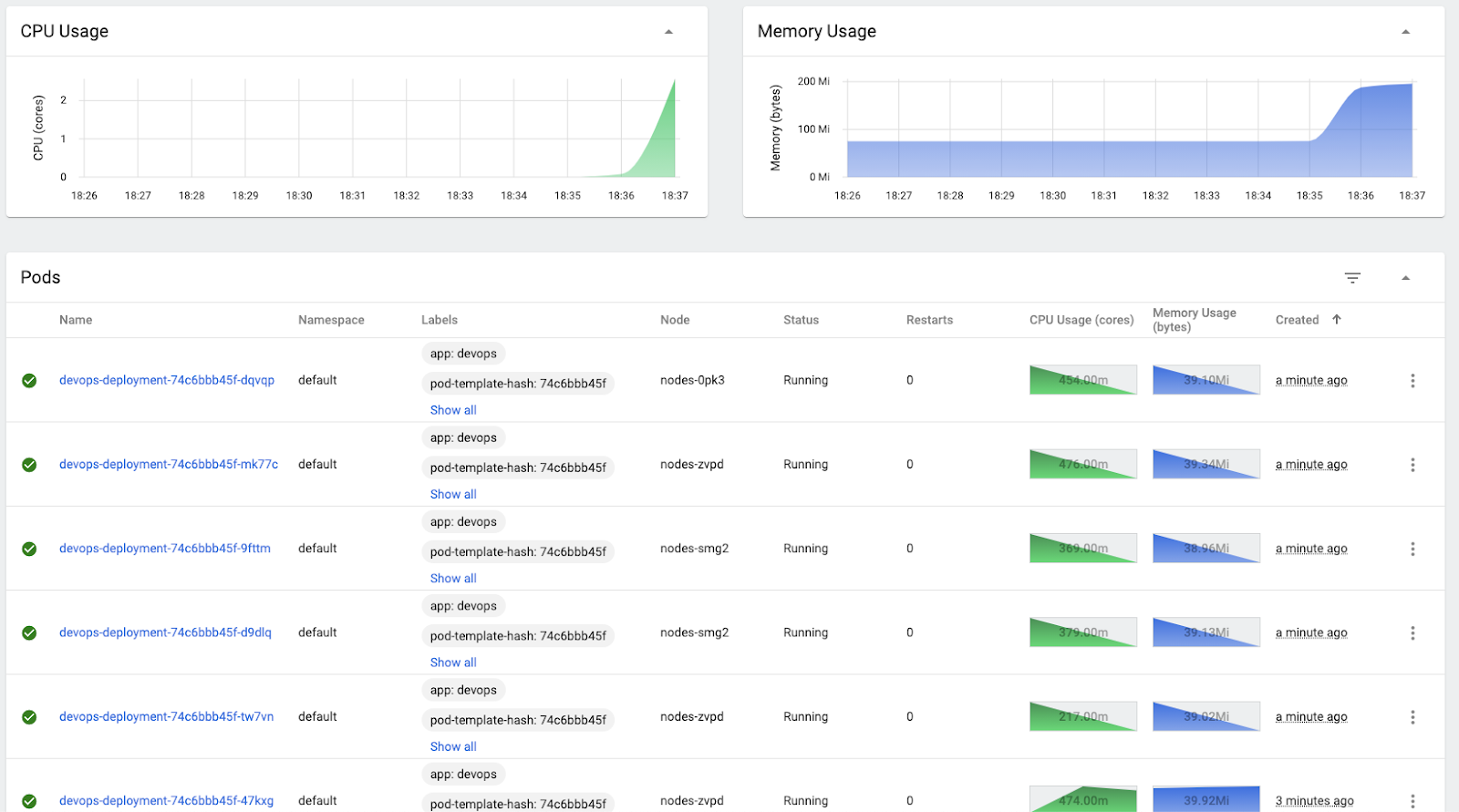
Wait for about 5 minutes after you've finished generating the requests. The pods should scale back to 5.
Delete the Deployment
It's just as easy to delete everything, as it is to create everything. Enter the following to delete the deployment. This will delete the deployment but not the cluster. We will delete the cluster shortly.
$ kubectl delete hpa devops-deployment
$ kubectl delete services devops-deployment
$ kubectl delete deployment devops-deploymentWait a minute and then type kubectl get pods and kubectl get services to see if everything got deleted.
Changing the instance group size
First, check how the InstanceGroups for your nodes and for your masters are called.
$ kops get ig
NAME ROLE MACHINETYPE MIN MAX ZONES
master-us-east-1a Master t2.small 1 1 us-east-1a
master-us-east-1b Master t2.small 1 1 us-east-1b
master-us-east-1c Master t2.small 1 1 us-east-1c
nodes-us-east-1a Node t2.small 1 1 us-east-1a
nodes-us-east-1b Node t2.small 1 1 us-east-1b
nodes-us-east-1c Node t2.small 1 1 us-east-1cLet's change the number of nodes in the nodes-us-east-1a instanceGroup to 2. Edit the InstanceGroup configuration:
$ kops edit ig nodes-us-east-1aIt will open the InstanceGroup in your editor, looking a bit like this:
apiVersion: kops.k8s.io/v1alpha2
kind: InstanceGroup
metadata:
labels:
kops.k8s.io/cluster: mycoolcluster.k8s.local
name: nodes-us-east-1a
spec:
image: 099720109477/ubuntu/images...
machineType: t2.small
maxSize: 1
minSize: 1
...Edit minSize and maxSize, changing both from 1 to 2, save and exit your editor. If you wanted to change the image or the machineType, you could do that here as well (and we'll do it in a few minutes). There are actually a lot more fields, but most of them have their default values, so won't show up unless they are set. The general approach is the same though.
On saving you'll note that nothing happens. Although you've changed the model, you need to tell kops to apply your changes to the cloud.
First, lets preview what the changes will look like:
$ kops update cluster
...
Will modify resources:
AutoscalingGroup/nodes-us-east-1a.mycoolcluster.k8s.local
MaxSize 1 -> 2
MinSize 1 -> 2
...Apply the changes:
$ kops update cluster ${NAME} --yesWithin ~2-5 minutes you should see the new node join:
$ kubectl get nodesInstance group rolling update
Changing the instance group size was a simple change, because we didn't have to reboot the nodes. Most changes to the node's configuration do require rolling your instances - this is actually a deliberate design decision, in that Kops is aiming for immutable nodes.
Let's try changing machineType to t2.medium. While we're doing it we will scale back the cluster.
Edit the InstanceGroup configuration:
$ kops edit ig nodes-us-east-1aIt will open the InstanceGroup in your editor, modify it so the minSize, maxSize and machineType field look like the next snippet:
apiVersion: kops.k8s.io/v1alpha2
kind: InstanceGroup
metadata:
labels:
kops.k8s.io/cluster: mycoolcluster.k8s.local
name: nodes-us-east-1a
spec:
image: 099720109477/ubuntu/images...
machineType: t2.medium
maxSize: 1
minSize: 1
...Now preview will show that you're going to create a new Launch Template, and that the Group Scaling Group is going to use it:
$ kops update cluster
...
Will modify resources:
AutoscalingGroup/nodes-us-east-1a.mycoolcluster.k8s.local
MaxSize 2 -> 1
MinSize 2 -> 1
LaunchTemplate/nodes-us-east-1a.mycoolcluster.k8s.local
InstanceType t2.small -> t2.medium
...Note that the MachineType is indeed set to the t2.medium as you configured.
Apply the changes:
$ kops update cluster ${NAME} --yesWithin ~ 2 minutes you should see that you scaled down to 3 nodes in the cluster:
$ kubectl get nodesBut if you check the machine types using aws cli - you'll see that they are still the same (t2.small), as you'll get only 3 t2.medium instances (our masters).
$ aws ec2 describe-instances --filters Name=instance-type,Values=t2.mediumThere's a hint at the bottom of kops update cluster command: "Changes may require instances to restart: kops rolling-update cluster"
These changes require your instances to restart (we'll remove the t2.small instances and replace them with t2.medium). Kops can perform a rolling update to minimize disruption.
To start the update:
$ kops rolling-update cluster --yesWhen the update is finished - check the machine types of the nodes:
$ aws ec2 describe-instances --filters Name=instance-type,Values=t2.mediumYou should receive 4 instances with t2.medium type.
Creating and deleting instance groups
Suppose you want to add a new group of dedicated nodes for some specific workloads (like having GPUs for ML). We can add taints and labels during instance creation.
But before we do this, let's add one more thing - make this a Spot Instance group.
A Spot Instance is an unused EC2 instance that is available for less than the On-Demand price. Because Spot Instances enable you to request unused EC2 instances at steep discounts, you can lower your Amazon EC2 costs significantly. The hourly price for a Spot Instance is called a Spot price. The Spot price of each instance type in each Availability Zone is set by Amazon EC2, and is adjusted gradually based on the long-term supply of and demand for Spot Instances. Your Spot Instance runs whenever capacity is available and the maximum price per hour for your request exceeds the Spot price.
Spot Instances are a cost-effective choice if you can be flexible about when your applications run and if your applications can be interrupted. For example, Spot Instances are well-suited for data analysis, batch jobs, background processing, and optional tasks.
Go to Spot Instance requests.
And click the Pricing history button.

In the pricing history, select:
- Graph - Instance types
- Instance types - t2.small
- Availability Zone - us-east-1a
- Platform - Linux
- Date range - 1 week
You should see a graph of average Spot prices for the last week. Note the value, as we'll double the average price as our max spot price in configuration.
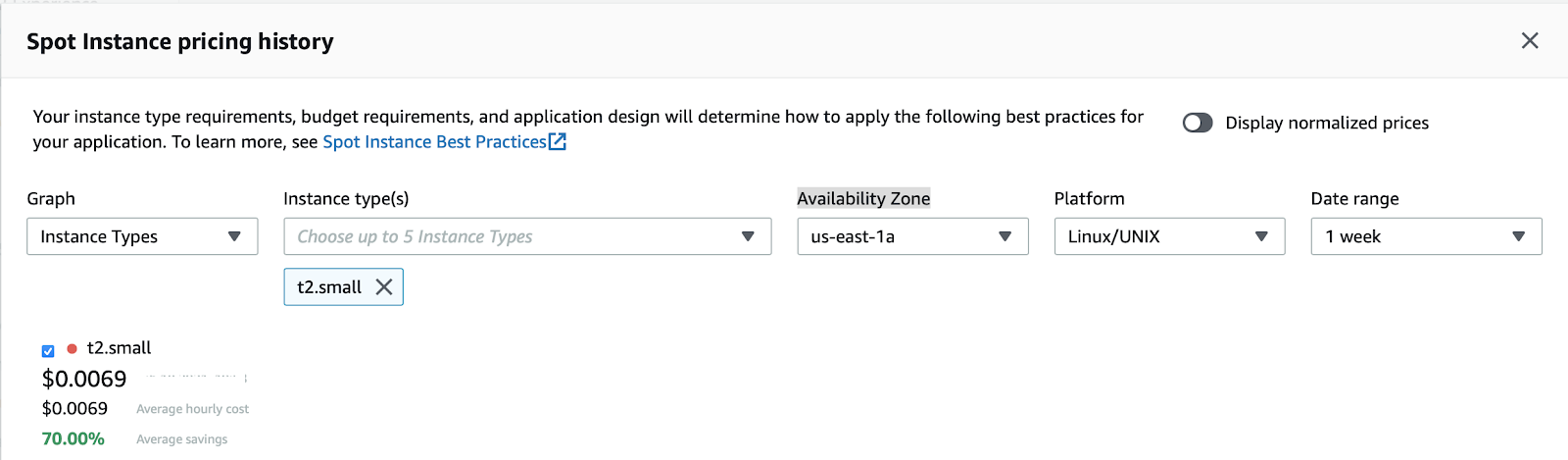
To create a new instance group run:
$ kops create ig gpu --subnet us-east-1aThe command opens an editor with a skeleton configuration, allowing you to edit it before creation. Completely replace it with the following configuration:
apiVersion: kops.k8s.io/v1alpha2
kind: InstanceGroup
metadata:
creationTimestamp: null
name: gpu
spec:
image: 099720109477/ubuntu/images/hvm-ssd/ubuntu-focal-20.04-amd64-server-20210119.1
manager: CloudGroup
kubelet:
anonymousAuth: false
nodeLabels:
node-role.kubernetes.io/node: ""
machineType: t2.small
maxPrice: "0.0140" # ~ double the average spot price
maxSize: 1
minSize: 1
taints:
- gpu=nvidia:PreferNoSchedule
nodeLabels:
gpu: "true"
kops.k8s.io/instancegroup: gpu
role: Node
subnets:
- us-east-1aApply the changes :
$ kops update cluster ${NAME} --yesWait for about 2-5 minutes and deploy our "ML" workload that might require GPU 😅:
$ cat <<EOF | kubectl create -f -
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
run: hello-ml
name: hello-ml
spec:
replicas: 2
selector:
matchLabels:
run: hello-ml
template:
metadata:
labels:
run: hello-ml
spec:
containers:
- image: nginx
name: hello-ml
ports:
- containerPort: 80
protocol: TCP
resources:
requests:
cpu: "50m"
tolerations:
- key: gpu
operator: Equal
value: nvidia
effect: PreferNoSchedule
nodeSelector:
gpu: "true"
EOFCheck where the pods are running. Both replicas should be on our "gpu" node:
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
...
ip-172-20-46-110.ec2.internal Ready node,spot-worker 14s v1.19.7
...The node name of the pods should be the same as the node name of the node with spot-worker role.
$ kubectl get pod -owide
NAME READY STATUS RESTARTS AGE IP NODE
hello-ml-f587988bd-hxntm 1/1 Running 0 9s 100.96.6.2 ip-172-20-46-110.ec2.internal
hello-ml-f587988bd-q5mq8 1/1 Running 0 9s 100.96.6.3 ip-172-20-46-110.ec2.internalFinally, delete the instanceGroup:
$ kops delete ig gpuTo delete the Ingress controller to terminate the LoadBalancer:
$ kubectl delete -f https://raw.githubusercontent.com/kubernetes/ingress-nginx/controller-v1.2.0/deploy/static/provider/aws/deploy.yamlTo delete the cluster execute the following command.
$ kops delete cluster --name $NAME --yesWhen the cluster is removed - delete the bucket.
$ aws s3api delete-bucket \
--bucket ${STATE_BUCKET} \
--region ${REGION}Thank you! :)